Clustered Index & Non-Clustered Index
on DB
Clustered Index & Non-Clustered Index
Index 생성
UNIQUE 제약 조건이 있는 테이블을 만들면 데이터베이스 엔진에서는 자동으로 Non-Clustered Index를 만든다.
Primary Key를 지정하는 열에 강제적으로 Non-Clustered Index를 지정 가능하다.
기존 테이블에 PRIMARY KEY 제약 조건을 적용하려 하거나 해당 테이블에 Clustered Index가 이미 있으면 Non-Clustered Index를 사용하여 기본 키를 적용한다.
제약 조건 없이 테이블 생성시에 Index를 만들 수 없으며, Index가 자동 생성되기 위한 열의 제약 조건은 Primary Key또는 Unique 뿐이다.
Clustered Index
Clustered Index를 책으로 비유하자면 페이지를 알고 있어서 바로 해당 페이지를 펼치는 것과 같다.
테이블 생성시 하나의 열에 Primary Key를 지정하면 자동으로 Clustered Index가 생성된다.
Clustered Index는 Index를 생성할 때마다 테이블의 데이터를 지정된 컬럼에 대해 물리적으로 데이터를 재정렬한다.
클러스터형 인덱스는 루트 및 중간 수준에 인덱스 키가 있는 B-트리 구조로 데이터를 정렬하고 저장한다. 테이블 내용은 B-Tree의 리프 수준에 저장된다.
데이터가 테이블에 삽입되는 순서에 상관없이 Index로 생성되어 있는 컬럼을 기준으로 정렬되어 삽입된다.
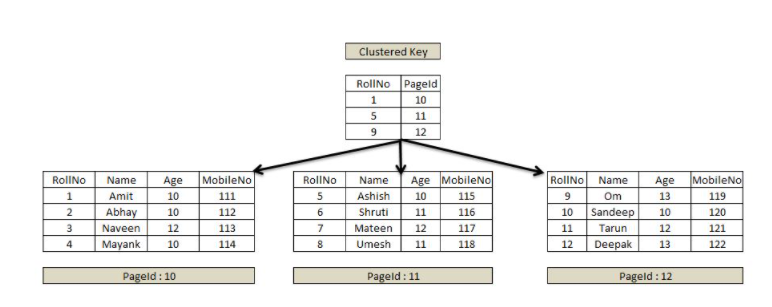
Index Page를 키값과 데이터 페이지 번호로 구성하고, 검색하고자하는 데이터의 키 값으로 페이지 번호를 검색하여 데이터를 찾는다.
Clustered Index는 테이블 당 한개씩만 존재 가능해 Index를 걸면 가장 효율적일거 같은 컬럼을 Clustered Index로 지정해야한다. ( Cardinality가 높은 컬럼 )
테이블에 데이터가 많이 저장된 상태에서 Insert나 ALTER를 통해 Clustered Index를 추가한다면, 많은 데이터를 정렬해야 해서 많은 리소스를 차지하게 된다. 따라서 사용자가 많은 시간에는 Clustered Index를 추가를 피해야한다.
Non-Clustered Index
Non-Clustered Index를 책으로 비유하자면 목차에서 찾고자 하는 내용의 페이지를 찾고나서 해당 페이지로 이동하는것과 같다.
Non-Clustered Index는 물리적으로 데이터를 배열하지 않은 상태로 데이터 페이지가 구성된다. 테이블의 데이터는 그대로두고 지정된 컬럼에 대해 정렬시킨 인덱스를 만들 뿐이다.
Non-Clustered Index는 Clustered Index보다 검색 속도는 느리지만, 데이터의 입력/수정/삭제는 더 빠르다.
Non-Clustered Index는 테이블 당 여러개 존재 가능하다. ㅋ함부로 남용하면 오히려 시스템 성능을 떨어뜨린다.